Before you start
- An Olostep account with an API key: get one free, no credit card required. Your first 500 credits are included.
- n8n running: either n8n Cloud or a self-hosted instance. Community nodes must be enabled (they are by default on most setups).
- No coding required: everything in this guide is done through n8n’s visual editor.
Setup
Search for the Olostep node
Open any workflow, click +, and search for Olostep. Select Olostep Web Scraper from the results.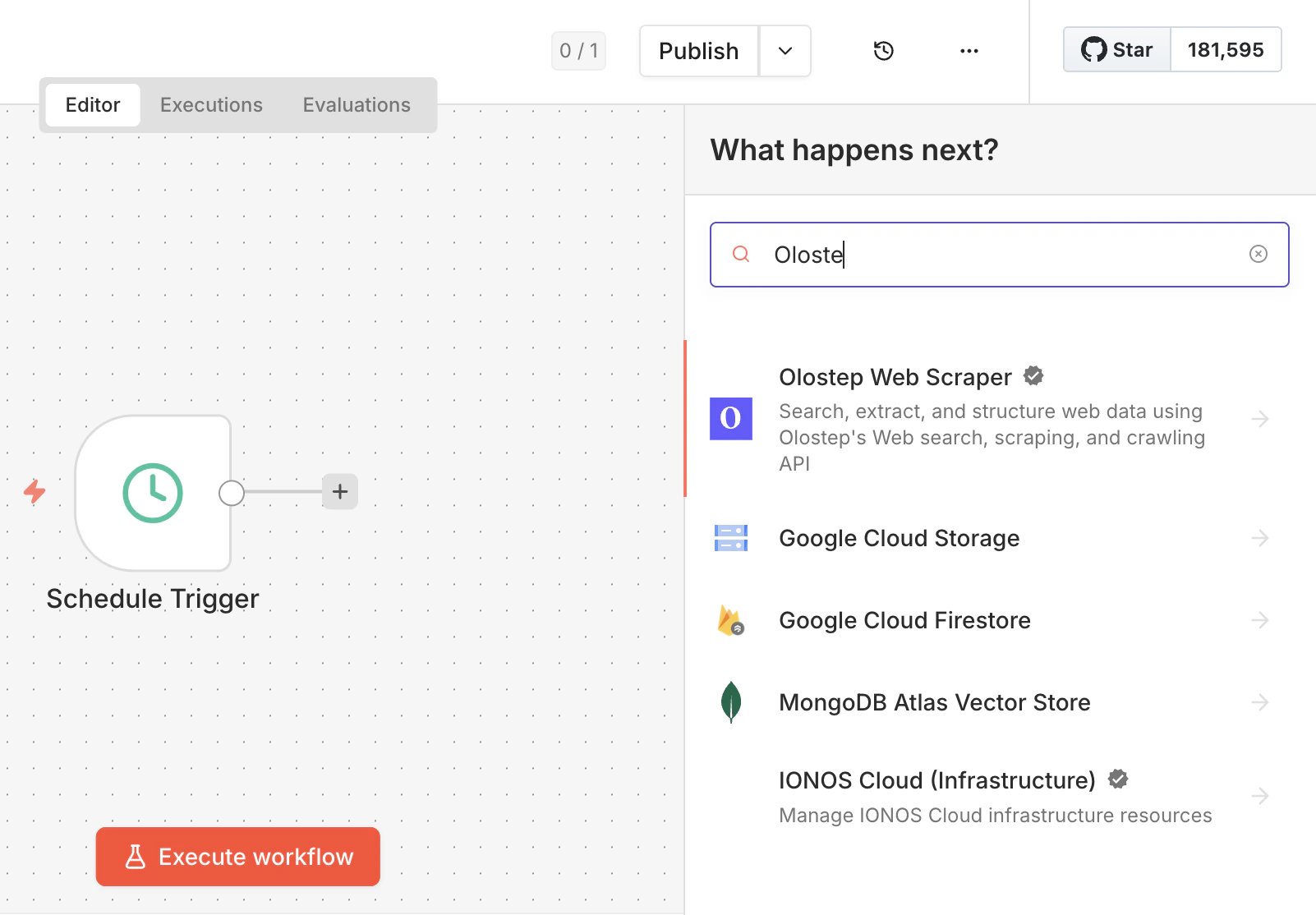
Install the node
Click the result to open the Node details panel, then click Install node. n8n will install 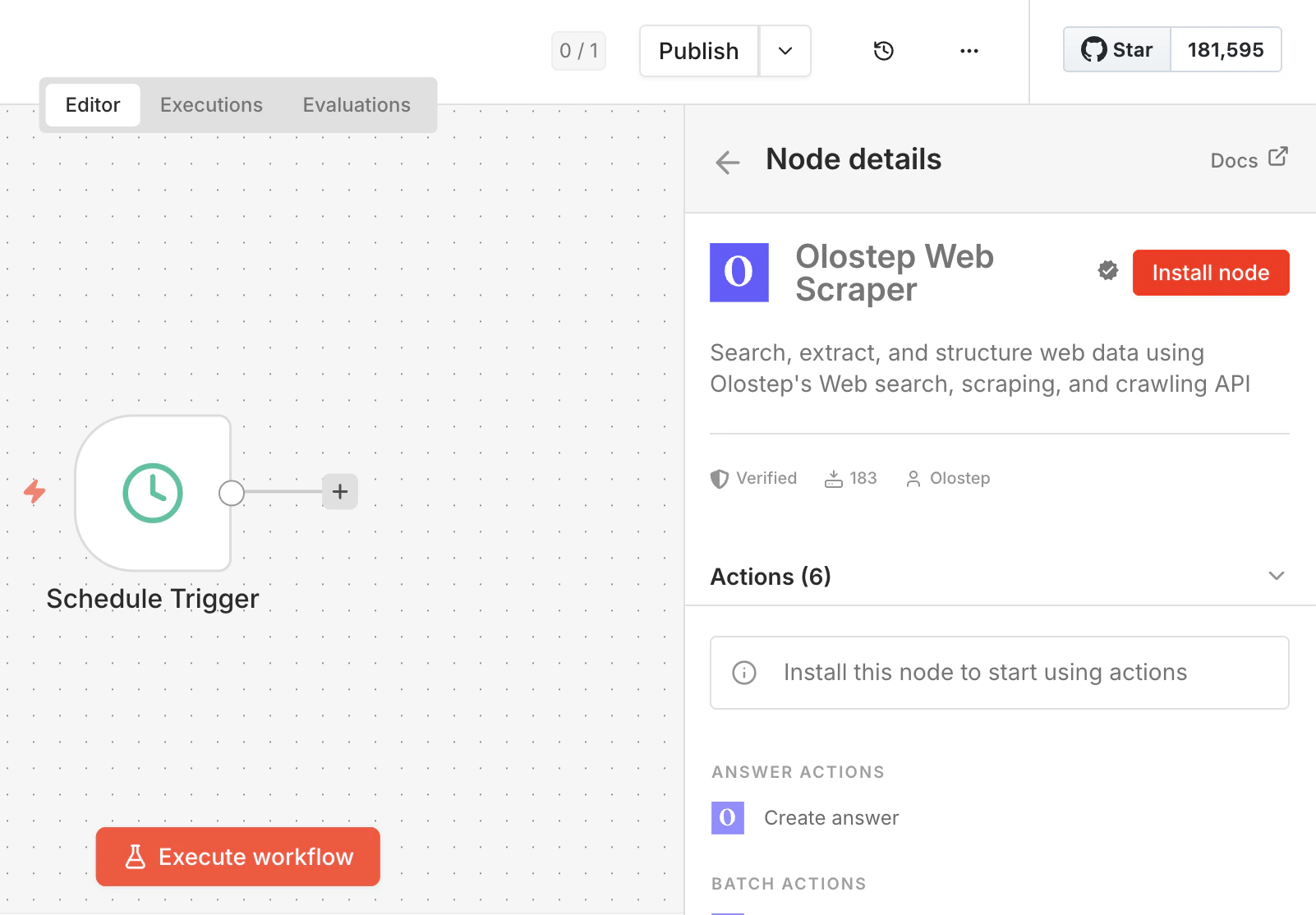
n8n-nodes-olostep and prompt you to restart. Do that before continuing.If Community Nodes is disabled for your workspace, an admin needs to enable it first. See the n8n community nodes guide.
Add your API key
Open the Olostep node in your workflow, click Set up Credential (in the Parameters tab), add your API key, and click Save.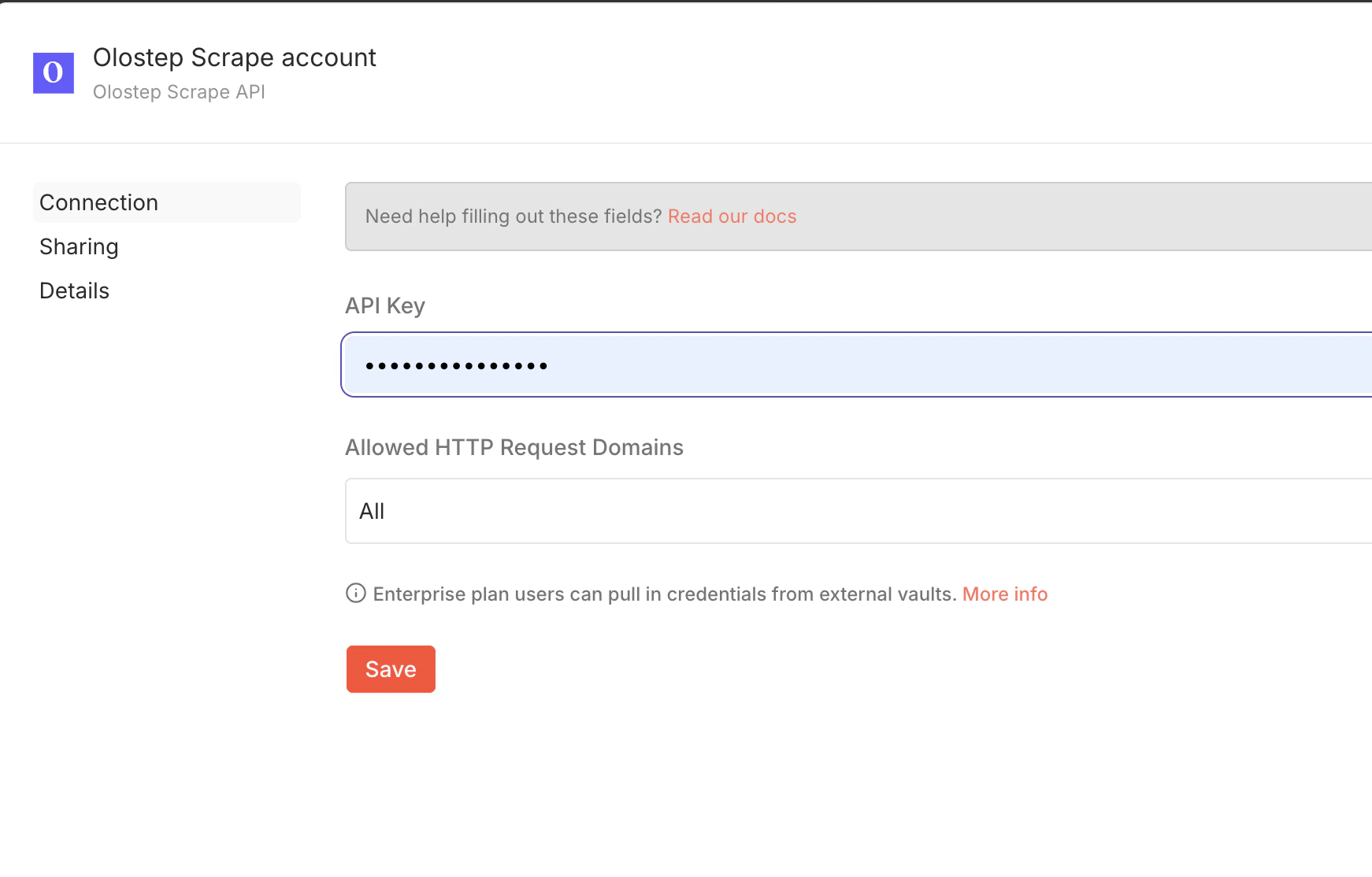
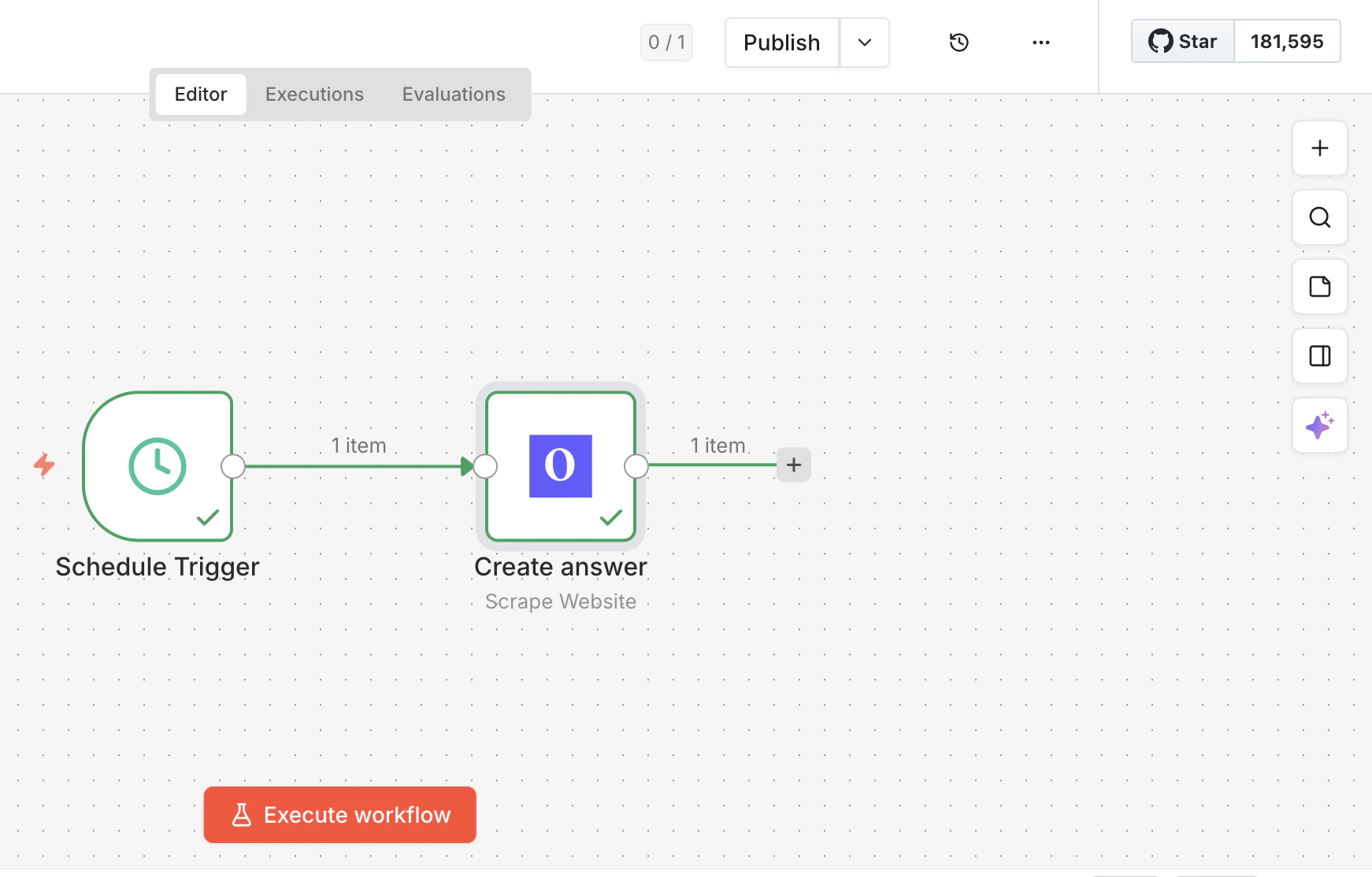
Actions
Scrape Website
Pull content from any URL as Markdown, HTML, JSON, or plain text. Handles JS-rendered pages with optional wait times and country targeting.
Search
Run a web search and get structured results (titles, URLs, and snippets) as JSON.
Answers (AI)
Ask a natural-language question and get an answer with cited sources. Useful before LLM nodes when you need grounded responses.
Batch Scrape URLs
Submit up to 10,000 URLs in one job, processed in parallel. Returns a
batch_id; retrieve results asynchronously.Create Crawl
Start from a URL, follow links, and scrape all subpages. Good for docs sites, blogs, or full-site ingestion. Returns a
crawl_id.Create Map
Get every URL on a site without scraping content. Use it for discovery before a batch job. Returns a
map_id.Batch, Crawl, and Map are async. Store the returned ID and use a Wait node or a second workflow to retrieve results once processing completes.
Example workflow: Lead enrichment from Google Sheets
What it does: When you paste a company URL into a Google Sheet, this workflow automatically scrapes the company’s website, extracts key information with an AI node, and writes the results back to the same row, turning a blank spreadsheet into a filled-out lead database. Nodes used: Google Sheets trigger → Olostep Scrape Website → OpenAI → Code → Google Sheets update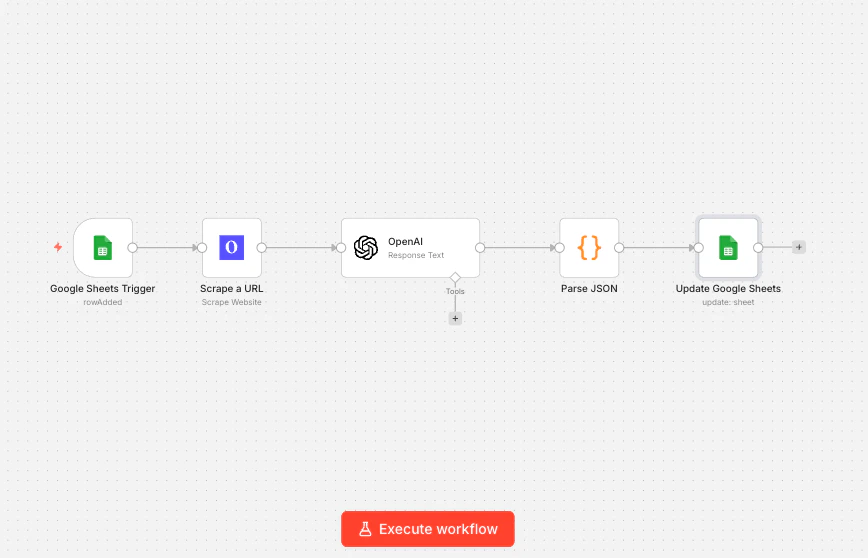
Step 1: Set up your Google Sheet
Create a sheet with these columns:Company URL, Industry, Description, Company Size, Enriched. The workflow reads from Company URL and fills in the rest.
Step 2: Add a Google Sheets trigger
In n8n, add a Google Sheets trigger node. Set the event to Row Added, point it at your sheet, and set it to watch theCompany URL column. Now every time you paste a new URL into the sheet, this workflow fires.
Step 3: Add Olostep Scrape Website
Connect an Olostep Web Scraper node after the trigger. Set:- Action: Scrape Website
- URL:
{{ $json["Company URL"] }}(pulls the URL from the new row) - Output Format: Markdown
Step 4: Add an OpenAI node
Connect an OpenAI node. Set the model togpt-4o-mini (fast and cheap for extraction tasks) and use this prompt:
markdownContent field is what Olostep returns from the scrape, as clean plain text.
Step 5: Parse the AI response and write back
Add a Code node to parse the JSON from OpenAI:Industry→{{ $json.industry }}Description→{{ $json.description }}Company Size→{{ $json.company_size }}Enriched→Yes
What you get
Paste a URL likehttps://notion.so into your sheet, and within ~10 seconds the row fills in:
| Company URL | Industry | Description | Company Size | Enriched |
|---|---|---|---|---|
| https://notion.so | Productivity SaaS | All-in-one workspace for notes, docs, and databases | Mid-market | Yes |
Templates
Ready-to-import n8n workflows built with Olostep:Crawl docs → AI knowledge base
Crawl documentation sites with Olostep and structure the output into an AI-ready knowledge base.
Google Maps leads → decision-maker enrichment
Scrape business leads from Google Maps and enrich them with decision-maker details.
Mine user complaints → insight report
Analyze complaints with Olostep + Gemini and generate structured insight reports in Google Docs.
Amazon product extraction → Google Sheets
Extract Amazon product URLs and metadata with Olostep, then sync the results to Sheets.
Parsers
Add a parser ID to the Parser field on any Scrape or Batch action to get structured data instead of raw content:| Parser | Extracts |
|---|---|
@olostep/amazon-product | Title, price, rating, reviews, images, variants |
@olostep/google-search | Result titles, URLs, snippets |
@olostep/google-maps | Business name, address, rating, reviews |
@olostep/extract-emails | Email addresses from any page |
@olostep/extract-socials | Social profile links (X, GitHub, LinkedIn, etc.) |
@olostep/extract-calendars | Google Calendar and ICS links |
Troubleshooting
API key rejected
API key rejected
Copy the key directly from olostep.com/dashboard with no trailing spaces. Delete and recreate the credential in n8n if the error persists.
Scraped content is empty
Scraped content is empty
Increase Wait Before Scraping (try 2000–5000ms for JS-heavy pages). Confirm the URL is publicly accessible without a login. If a specific domain is consistently failing, contact info@olostep.com.
Batch URL format error
Batch URL format error
The URLs to Scrape field expects a JSON array:Use a Code node upstream to build this array from your data if needed.
Rate limit hit
Rate limit hit
Add a Wait node between scrape steps, or switch to Batch Scrape URLs instead of looping single scrapes. Check current usage in the dashboard.
Community Nodes not visible in Settings
Community Nodes not visible in Settings
On n8n Cloud, community nodes must be enabled by a workspace owner. On self-hosted, make sure
N8N_COMMUNITY_PACKAGES_ENABLED=true is set in your environment. See n8n’s installation guide.Related
Scrapes API
Full reference for the scrape endpoint
Batches API
How batch jobs work and how to retrieve results
Crawls API
Crawl configuration and result retrieval
Maps API
URL discovery and filtering options
Get Started
Ready to automate your web search, scraping, and crawling workflows?n8n Website
n8n platform
Install the Node
Install n8n-nodes-olostep and start building automated workflows